Software > Simple Graph Match Algorithm
Description | Pros and Cons | Applications | Details | Usage Hints | References | Acknowledgments
| Description |
Networks are represented as graphs with nodes and edges. In a network setting, an interaction within nodes is shown by a connecting edge. For example, network of authors, friends, proteins etc. Given two networks with similar information content, a common approach is to identify the shared content.
A 'Simple Match' algorithm discussed here uses the node label information
to identify the overlap between two given networks. The algorithm sifts
through the two networks to identify nodes that share the same node label
string.
| Pros & Cons |
Simple match is a string matching algorithm. It is a quick way to identify the common information content within the two networks. Presently the algorithm is not restricted to any particular network size.
The algorithm does not favor structural match. So it cannot be used to identify similar structure that exists within two given networks.
| Applications |
It is general graph matching algorithm that can be used to map systems that can be represented as graphs.
- Ontology mapping
- Database schema matching
| Details |
The algorithm is implemented is Perl. The algorithm accepts network files in pajek format (.net) having vertices and arcs information. It performs a search for common nodes within the two networks. The resultant file is a pajek file with over-lapping and non-overlapping information which can be directly visualized in Pajek. This kind of visualization is more suitable for a small size networks.
A sample visualization of common nodes shared by network 1 (green) and network 2 (red). The common nodes are connected by black edges.
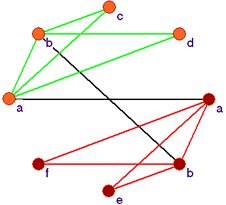
| Usage Hints |
To run
The perl script (p_simple-match.pl) requires three arguments as inputs from the user. Pajek formats files for network 1 (nw1) , network 2 (nw2) and output file name.
Syntax: perl p_simple-match.pl
<nw1> <nw2> <output file>
Output file can be fed to Pajek to obtain the visualization.
| References |
-
Batagelj, V. and A. Mrvar, Pajek (1997). Program Package for Large Network Analysis, University of Ljubljana, Slovenia. Avaliable http://vlado.fmf.uni-lj.si/pub/networks/pajek/ .
| Acknowledgments |
This documentation was compiled by Ketan Mane and Katy Börner. .
![]()
Information
Visualization Cyberinfrastructure @ SLIS,
Indiana University
Last Modified March 10, 2005