Software > XML Toolkit
This web page describes the general architecture of the XML toolkit and explains how new code can be integrated.
XML Toolkit Architecture
The unified toolkit architecture aims to provide a flexible infrastructure in which multiple data analysis and information visualization (IV) algorithms can be incorporated and combined. It aims for “tightly coupled visuals but loosely coupled code.”
The current structure allows concurrent visualization and interaction with the same datasets accessed through standard model interfaces. The supported models include the TreeModel, TableModel, and ListModel which are part of the standard Java edition (J2SE) along with the MatrixModel and NetworkModel which are additional interfaces supported in this framework.
A persistence factory is utilized to enable a general and interchangeable layer for persisting and restoring those various data models. The persistence could be to an object database, a flat file, XML datastore, etc.
The implemented persistence layer is an XML-based interchange format that is used to unify data input, interchange, and output formats. The factory and interface classes allow all software packages to implement and to use a defined XML schema set that is hidden away in the persistence layer of the toolkit. This ensures that software packages can be easily interchanged, compared, and combined through the models that are generated instead of an algorithm-by-algorithm direct use of the XML structure. Also simple configurations of the XML input format suffice to use different algorithms in a wide variety of applications as they may produce different model types that are supported by different IV algorithms. Finally, all the Java-based algorithms can be run in stand-alone mode as an applet or application.
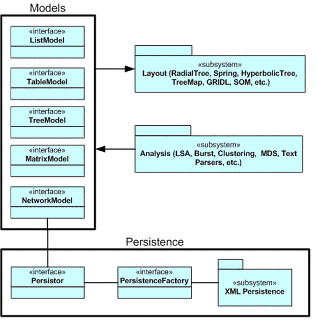
Figure 1: General Architecture of the XML Toolkit
The general structure of the repository XML toolkit, depicted in Figure 1, relies on the use of factory and interface classes to interact with various data analysis algorithms and to instantiate and populate the various algorithms. Each algorithm class must implement at least one of the model interfaces for its internal data model in order to be registered with the toolkit. The XML data and the interfaced objects are managed through the persistence layer and the model interfaces that control access of the data and its population into the objects.
Integrating New Code
The process to integrate code is to either build code using at least one of the supported model types (e.g., ListModel, TableModel, TreeModel, MatrixModel, or NetworkModel) or to program a wrapper to interchange from their algorithm's data representation to one of the interfaces. There is also an interface for processing formatting options called IVFormat which generalizes some of the general node and edge format options (background, foreground, font, size, etc). The toolkit can work without the IVFormat interface as the defaults are all populated for different formatting options.
Acknowledgements
Jason Baumgartner, Nihar Sheth, Nathan J. Deckard, and Katy Börner are the 'Master Minds' behind this XML toolkit effort. They specified the general functionality of the toolkit, determined its architecture, and organized the resources to bring it to life. Since fall of 1999, the following students have been involved in this effort: Yuezheng Zhou, Min Xiao, Sriram Raghuraman, Nihar Sanghvi, Sidharth Thakur, Todd Holloway, Ketan Mane, Benjamin Ashpole, and Ning Yu.
![]()
Information
Visualization Cyberinfrastructure @ SLIS,
Indiana University
Last Modified January
14, 2004