Software > Burst Detection
Description | Pros and Cons | Applications | Details | Usage Hints | References | Acknowledgments| Description |
The Burst Detection algorithm has been developed and provided by Jon Kleinberg (Cornell University). The algorithm aims to analyze documents to find features that have high intensity over finite/limited durations of time periods. Rather than using plain frequencies of the occurrences of words, the algorithm employs a probabilistic automaton whose states correspond to the frequencies of individual words. State transitions correspond to points in time around which the frequency of the word changes significantly.
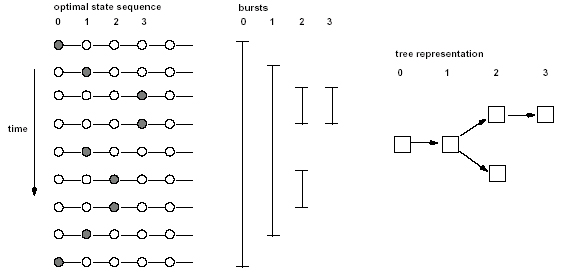

The algorithm is intended to extract meaningful structure from document
streams that arrive continuously over time (e.g., emails or news articles).
It generates a ranked list of the most significant word bursts in the
document stream, together with the intervals of time in which they occurred.
This can serve as a means of identifying topics or concepts that rose
to prominence over the course of the stream, were discussed actively for
a period of time, and then faded away.
An advantage of the implementation is that no pre-processing is performed
on the documents (we simply eliminate all non-letter characters and down-case
all words). Burst analysis is performed for all words (including stop-words
such as `the').
The algorithm itself is described in this
paper (PDF).
| Pros & Cons |
Often, one is not only interested in the frequency of word occurences,
e.g., in publications, but also the sudden increase or decrease in word
usage. The burst algorithm provides a scalable means to identify burst
of word frequency activity in text data streams.
| Applications |
Two sample data sets were used by Kleinberg to demonstrate the algorithm:
- The set of all U.S. Presidential State of the Union Addresses, 1790-2002 (linked here).
- Titles of papers from computer science conferences over the past few
decades. In this context, automatically extracted bursty terms suggest
research topics that were in fashion for a period of time (linked
here).
The animal behavior data set comprising journal and article records was downloaded from the Biological Abstracts database. The burst algorithm was then applied to publications from a core set of 11 journals and the TITLE of the records were used to provide the text for burst detection.
Several results were obtained and are available for download:
- First, the TITLEs were used 'as-is', i.e. without removal of stop-words. However, special characters were removed. The results are available here .
- Next, the results with stop-words removed were obtained. The results are available here.
- A visualization was generated to describe the span of the words. The visualization data is described here; the enhanced image is available here.
{kind=link}
| Details |
The project files are located on the 'iuniverse' server under '/u4/iv/IVR/src/edu/iu/iv/analysis/burst/' folder and are organized as follows:
| Docs/Events | Location |
| burst | Project root folder |
|
Data files |
docs |
Documents - instructions, communications, etc.
|
src |
Source files
|
| Usage Hints |
The Burst Detection C-code can be compiled with the generic 'cc' compiler
at the unix system prompt. The '-o' option can be used to generate the
custom executable file. Sample data exists in the 'networking.index' file
and is constructed from paper titles at the two CS networking conferences
SIGCOMM and INFOCOM, 1988-2001.
The original C-code is run by the following console command:
-bin -eps : they are just required - no explanation in code.
-rel 2 2 1: in order, they stand for:
ratio of rate of second state to base state
ratio of rate of each subsequent state to previous state (for states >
2)
number of states minus 1
-trans 1 : gamma parameter of the HMM.
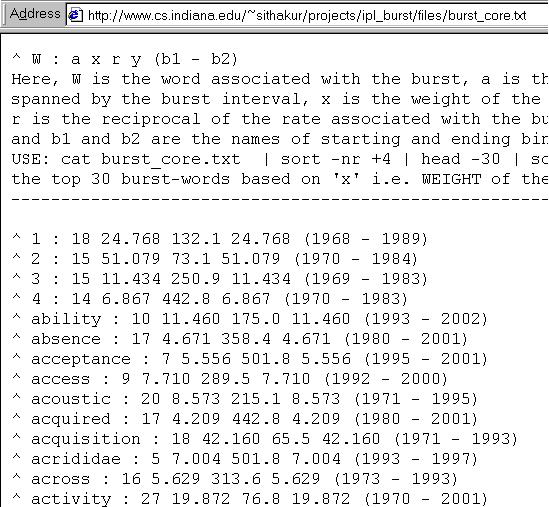
Output is in the following format:
^ abr : 2 6.915 68.0 6.915 (1997 - 1998)
^ access : 2 6.865 14.8 6.865 (1989 - 1990)
^ ...
Each line reprsents a single burst, in this case in the two-state model.
It has the form
Here, W is the word associated with the burst, a is the number of bins spanned by the burst interval, x is the weight of the burst, r is the reciprocal of the rate associated with the burst state, and b1 and b2 are the names of starting and ending bins.
| References |
- J. Kleinberg. Bursty and Hierarchical Structure in Streams. Proc. 8th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining, 2002. Slides.
- J. Kleinberg. Structure of Information Networks. Slides.
| Acknowledgments |
The Burst Detection package was developed by Jon Kleinberg. It was integrated by Todd Holloway (tohollow@cs.indiana.edu) and Sidharth Thakur (sithakur@indiana.edu). Sidharth Thakur and Katy Börner wrote the documentation.
![]()
Information Visualization Cyberinfrastructure
@ SLIS, Indiana University
Last Modified January 14, 2004